5 Development of a Prototype JITM System
|
This section details the development of a prototype JITM system to demonstrate and test some of the advantages of the JITM paradigm. A copy of the prototype accompanies this report on a floppy disk. Instructions for installing the prototype are included on the floppy disk and the prototype includes built-in help facilities. 5.1 The Prototype Development EnvironmentHyperCard v2.2 on the Macintosh was the development environment chosen for the creation of the prototype. The choice of development environment was partly determined by available resources, but the ASEC has already used HyperCard for the development of other text-based applications for use in this field and its capabilities for this type of work are known and respected. The rest of this section details briefly some of HyperCard’s advantages and how they are relevant to this project. 5.1.1 Interface Building CapabilitiesThe HyperCard environment is based on the metaphor of a stack of cards, where each card represents one item in a set of items represented by the whole stack. The stack environment also makes use of some of the features of object-oriented systems. Specifically, it features message passing between objects, method inheritance and exceptions. The HyperCard environment has a built-in hierarchical structure. The code contained in an object’s method is converted into messages which are passed up through the hierarchy to be interpreted or "handled" by other objects in the environment. Messages can be "handled" at any level of the tree. Therefore specific cards can be individually customised with features for presenting and manipulating the information held on that card, and also make use of methods available globally to the whole stack. Since only one card is visible in a stack at any one time, careful grouping of information and features make this environment extremely useful for interactive presentations such as is required for our prototype presentation. A subtle, but important, advantage of the HyperCard environment is its use of familiar interface controls and features. HyperCard gives the stack developer access to the majority of the MacOS interface features and controls (eg. menus, buttons, styleable-text fields, etc). Its features and controls all conform to the standard MacOS user interface guidelines [Apple, 1988] and therefore their operation is familiar to anyone who has used the MacOS. They should also be easily recognised by users of other graphical user interfaces, as the guidelines stress intuitive operation. This set of features and interface controls is rich enough to fulfil all the presentation and control requirements for the prototype and so no further effort was required to develop custom interface features. 5.1.2 Text Handling CapabilitiesAlthough mostly known for its multimedia capabilities, HyperCard has always had very versatile text manipulation capabilities through its scripting language, "HyperTalk". HyperTalk uses the concept of a container as its standard variable mechanism. Containers are typeless variables which contain character strings of any length, that can be interpreted and manipulated as required. Therefore a HyperCard container can hold an arbitrarily long string of numerals, which can be converted to a numerical value for a calculation, but could also be manipulated using string manipulation utilities. This facility is demonstrated in the following fragment of HyperTalk script. Which gives the result
A HyperCard container can hold a string of characters of any length, constrained only by available memory. This makes it very useful for handling arbitrarily long pieces of text. It should be noted that text placed into a container does not retain any character formatting, but in this application we are dealing with ASCII encoded texts so this limitation is not a problem. The HyperTalk scripting language contains the means to refer to any segment of a container down to the individual character, using what are referred to as "chunking" expressions (see above). The chunking mechanism of HyperTalk has some powerful features including the recognition of the delimiters most often found in texts (i.e. spaces and lines). This allows us to create chunking expressions such as demonstrated in the following line of script;
The availability of these text manipulation capabilities in HyperTalk was the major factor in determining the selection of HyperCard as the development environment for the prototype of the JITM system, as they eliminated the need to develop a tokeniser for the prototype. 5.2 Implementing Key Aspects of the JITM SystemThis section covers some of the more interesting aspects of the creation of the JITM system prototype in the chosen development environment. 5.2.1 Simplification of Word Token DelimitersFor efficiency reasons the definition of a word token delimiter for the transcription files was changed for the prototype JITM system. The allowable word token delimiters were restricted to one, the ISO 646 space character. This made the parsing of the word tokens into linked lists faster. As a side effect, by removing all other white space characters from text elements we reduce potential cross platform difficulties caused by different implementation of the end of line. 5.2.2 The Implementation of Linked ListsAs detailed in the chapter on system design, the JITM paradigm uses linked lists to insert tags into a transcription file without causing the reordering of the word tokens. HyperCard can easily create such data structures at the card level by creating a card for each list item and storing the unique IDs of the preceding and succeeding list elements in text fields on the card. However HyperCard writes to disk whenever the current card is changed (as a safeguard against losing data), so this would prove too slow for the current application. We want to be able to make linked lists down to the individual character level if necessary. HyperCard’s temporary, memory-resident data types are character string-based containers as mentioned previously. For the prototype we had to devise a way to simulate a linked list within a single container. To do this in the prototype system we have tightened the file format specification so that the only allowable word item delimiter is the space character. Since tabs, carriage returns and linefeeds are then not normally found within the body of a text element they can be used to provide internal structure to a container. HyperCard chunking expressions then enable easy manipulation of these structures. Simply put, to create a simulated linked list within a container, replace all occurrences of the list item delimiter (i.e. normally the space character for word tokens) with a carriage return character (i.e. ASCII character 13) as is shown in the example below.
becomes
Since each word token of the original text string now occupies its own line in the container, extra characters can be added to the contents of each line without destroying the indexing of the word tokens. The following example demonstrates how a text string can have multiple tags embedded without having to recalculate the word indices. The example uses simple HyperTalk text manipulation commands for brevity, but the actual code used in the prototype is similar in operation.
These lines of code when applied to the container in the previous example result in the container’s contents being changed to the following;
Converting from the linked list back into the text element gives;
The same process can occur at the character level of a single word token, by placing individual characters of the original word token on separate lines, and making changes as previously demonstrated. This requires the instantiation of a new level of linked list to be processed as a sub-task of the processing of the word token linked list. The linked list created, when processing a word token, must convert back into a single line of the linked list of word tokens for the text element. Note that the embedded "<emph>" tag in the example above contains a space character. The changed text element will no longer convert into the same linked list. This has two ramifications for the implementation of the linked list mechanism. First, all tagging of a text element must take place during the same instantiation of the linked list representing that text element, to ensure that the indexing of the linked list is the same for all tagging. Second, the tag sets to be applied to a transcription file have to be sorted based on their position in the transcription, so that all tag insertion for a text element can be done simultaneously. 5.2.3 The File Authentication Mechanism.Each tagRecord holds a copy of the "fileKey" for the transcription file it was created from. The fileKey for the proposed system uses a key generated from two components. The first is a human understandable string of characters to assist in identifying the appropriate file from the key. The second component is the MDC. To be a valid tagRecord for a transcription file, the MDC component of a tagRecord’s fileKey has to match the MDC calculated for the transcription file. As detailed in the section on system design, the authentication mechanism required for the JITM system is best described as a Manipulation Detection Code(MDC). Instead of using one of the hashing algorithms available in the literature, the prototype uses a simple function based on the character content of the file as shown below;
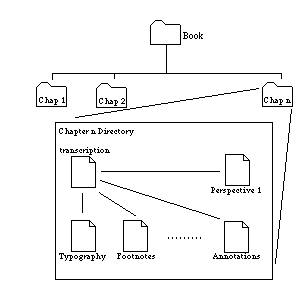
This function does not guarantee a unique value for MDC, but because the value generated is very position dependent, it is unlikely to create matching file keys by accident. Moreover it is relatively fast. The small size of the transcription files prevents the numbers involved in the calculation from getting too large for the arithmetic routines invoked in the function to handle. Although HyperCard’s typeless containers can hold arbitrarily long numbers stored as strings of characters, special procedures must be used to prevent overflow when they are converted to numbers for calculation. For the prototype, further investigation into a suitable function for generating a MDC was not considered necessary, as the goal of the authentication scheme in the JITM paradigm is more a consistency check rather than a security issue. The malicious manipulation of fileKeys within tagRecords is certainly a possibility, but in the researcher’s opinion this is a self-limiting problem as the JITM paradigm’s requirement of matching explicit fileKeys against a value calculated from the relevant text elements means that the spread of incorrect versions of either type of file will eventually be detected by the use of the bogus versions of a file with correct version of the file it relates to. Determining which is the authentic file may require referring to a third party to determine which of the files is correct, but at least the propagation of the incorrect file should be terminated. 5.2.4 The File Structure of the JITM PrototypeInstead of making use of a database for storing the data types of the prototype JITM system as recommended in section 4.5.2, "Data Storage for a JITM Electronic Edition", the prototype uses the file system of the host computer as its storage mechanism. The simpler system demonstrated here also demonstrates that the JITM paradigm can be a low technology solution (i.e. not tied to any proprietary software) which will hopefully mean that it will be good for archival purposes. Most computer operating systems have hierarchical file systems. This is directly analogous to the inherent structure of written works (i.e. volumes, chapters ...) and the hierarchical structure implicit in SGML. The JITM system makes use of this similarity for storing its components in a logically intuitive and consistent manner. Segments of the transcription are stored in separate sub-directories with their associated meta-data files as shown in the diagram below.
Figure 3. File System for JITM System. Breaking up the transcription of the work and its associated meta-data in this manner should also bring about some efficiencies in the JITM system implementation. Breaking up the transcription into smaller pieces is useful as only the section that is currently required for display need be processed, an important consideration in a system that needs to do a lot of string insertion in memory. There is also nothing preventing the permanent caching of JITM perspective files in these directories for immediate retrieval at a later time, allowing a specific user to customise their system for more efficient response to their usage patterns. At the cost of having to use longer pathnames for references between different segments of the transcription, this storage paradigm also allows us to use simpler relative file names for the meta-data files that apply to a specific segment (i.e. the emphasis tag set would have a simple name like "emphasis.jitm"). Its location in the directory hierarchy would be indicative of the section of transcription that it applied to and the fileKey of the tagRecord would prevent it being mistakenly applied to any other section. Simpler file names have the added benefit of making it easier to implement a tag set selection method, as the selection of available tag sets should be obvious from the local directory listing. 5.3 Prototype LimitationsThe main disadvantage to using HyperCard as the development environment for the JITM prototype was the definition of the text chunking delimiters. The definition of a word as a chunking expression entity includes any adjacent punctuation marks, with spaces and carriage returns being the only recognised word delimiters. This meant that in the prototype, when text strings are tokenised into word tokens for processing, they are tokenised as HyperCard word chunks rather than grammatically correct words. This is done for efficiency. The alternative, of recognising punctuation marks as separate word tokens, should be investigated for a production system. The other disadvantage is one of performance. HyperCard is an interpreted, object-oriented environment. It uses messages passed from object scripts up the hierarchical structure of the stack to the HyperCard application, which interprets the messages and executes them. Code interpretation is slow. Although the interpreted environment does aid in the development cycle by allowing for a very convenient tracing and debugging environment, the finished routines are slow at processing large examples of text. HyperCard allows for the extension of the HyperTalk language with compiled code external commands, called "XCMD"s, which can be added to the environment to perform processor intensive functions at compiled speeds if required. The JITM prototype does make use of some of these XCMDs. One is called, "fullReplace", and was developed by Frederic Rinaldi (available from the "Rinaldi Collection" of XCMDs available from Apple Computer® for non-commercial use). This XCMD is used to speed up the creation of the linked lists used in the prototype. The other, developed by the author, is called "CalculateMDC". It is used to calculate the MDC of the transcription file for matching against the fileKey stored in the tagRecords. The XCMD was developed using Heizer Software’s® "CompileIt™" XCMD Development System. 5.4 The Demonstration SoftwareIncluded with this report is a high density floppy disk formatted for the Macintosh Operating System. On it is a self extracting archive containing a prototype application of a JITM system generated from HyperCard v2.2. According to the HyperCard manual, the application will run on any Macintosh running System 6.0.5 or later and having at least 4 megabytes of RAM. However the application has only been tested on Power Macs running System 7.5.1 and MacOS 8.1. The self extracting archive should be uncompressed onto a local hard drive for best performance. The prototype application demonstrates the operation of a JITM system on some sample text. It includes a simple JITM-aware text editor that demonstrates some properties and features that would assist in the creation of tag sets for use in a JITM system. The prototype uses standard Macintosh control items and includes built-in help screens describing the operation and features of all the cards of the prototype. The rest of this section describes features of note in the prototype. 5.4.1 Perspective ViewerThe first card of the prototype is a demonstration of how the JITM system can generate SGML documents on demand from a user specified set of features. The viewer makes use of the JITM paradigm’s authentication scheme and automatic checking for conflicting structures in the applied tagging. This section discusses how both these features can be demonstrated on the prototype. The tag sets chosen by the user should only be applied to the transcription file that they were created for. This is done by matching the fileKey of the tagRecords against the MDC for the file to be modified. To represent this feature the viewer shows the MDC for the current contents of the text window in a small field at the top of the screen. Modification of the contents of the text window will cause this value to be recalculated when the cursor leaves the window. The user should experiment with this feature and verify for themselves that any modification of the transcription invalidates the creation of a perspective. Two tag sets have been supplied to demonstrate how the prototype JITM system handles perspectives that use tag sets with conflicting structures. They are the "Emphasis" tag set and the "Markings" tag set. The user should try to create a perspective using these two tag sets and notice how the prototype system detects and flags that there is a conflict. The prototype notifies the user that a conflict has occurred and indicates what tag sets are causing the conflict. It then completes the markup of the transcription file so that the user can see the conflicting hierarchy. The resulting document would not be parseable. 5.4.2 JITM Text EditorThe Text Editor is a simple example of the sort of tools which would need to be developed for the creation of a JITM-based electronic edition. Special tools like the text editor would be required because of the paramount importance of authenticity of the transcription files. This section discusses the three major features that are required for a JITM aware text editor. The editor is engineered to allow the user to add markup to the transcription file in a controlled way, so that there is no chance for the inclusion of accidental variants into the transcription. Tools are provided in the editor to assist the user in the correct marking up of the file. The editor can also be used to demonstrate the conversion of a marked up document into a linked list, so that tagRecords can be extracted from a marked up document. The text editor uses a combination of menu disabling and keystroke filtering to prevent the accidental deletion or overwriting of text from the transcription. As feedback, any text added to the transcription is underlined and can be manipulated as normal. If the user attempts an action that would delete or overwrite text from the original transcription, the action is prevented and a warning message to this effect appears on the screen. The user should experiment to verify that the original content of the transcription file cannot be removed. When the user enters the text editor, a "TAGS" menu appears in the menu bar. This gives the user access to some tools to assist the user in the correct tagging of the transcription file. Tags entered through the menu commands are smart tags in that the editor attempts to ensure that any element created has both start and end tags. Selecting a portion of the text and accessing one of the menu items in this menu will correctly bracket the selected text with the specified start and end tags. Using the menu to insert a single start tag for an element will place the element instance onto a stack of elements ready for closure. This stack is used by the text editor to prompt the user to correctly close elements. However at the moment the editor is not strict about constraining the user’s actions and other actions may be done after the start tag of an element is created. In this case it is not guaranteed that the editor will correctly prompt for the closure of the elements that have been previously opened. For a production system one means of fixing this limitation would be to force the user to always close an element immediately after the placing of a start tag by restricting the available actions of the editor to only this action. Further work on this aspect of the user interface, involving looking at how existing SGML editors handle this situation, will need to be done to determine what is the best solution if tools of this nature are required. At the bottom of the card there are buttons that allow the user to examine the process of extracting tagRecords from a marked up document. The user should attempt to verify this; first reset the text, insert some tags into the transcription file; parse the document into a linked list and then extract the tags. While doing this the user should verify that the inserted text is always associated with one of the pre-existing word tokens of the transcription file and that this association is carried over into the tagRecord representing the extracted meta-data. |