4 JITM Paradigm Design
4.1 Defining the Reference SystemThe JITM paradigm’s reference scheme considers the transcription of the historical work to be a text. In this case we create a new definition by amalgamating the two definitions of text;
This definition excludes the recording of certain typographical features of the original source such as page layout and emphasis. This is done purposefully. In the JITM paradigm both these aspects of the work are abstracted away from the transcription as they could bias the use of the transcription file. In the first case the layout of the original source is an artefact of the original medium. In the presentation of the transcription it might be useful to display the original pagination and lineation, but why should a user not be able to make the most use of the different proportions of a computer screen. In the second case the emphasis of the original source would have to be indicated using some sort of embedded tags. For this reason it is removed from a JITM transcription for although emphasis modifies the meaning of a word to a human reader the inclusion of tags within the text may bias the computer processing of the text for applications which are more statistically-based such as word frequency analysis. It should be emphasised that the JITM paradigm makes both these aspects of the original source available, but makes them optional. The term ‘entity reference’ in the definition is for the case where characters or other typographical marks used in source document are not supported by the ISO 646 character set (eg. mdash and accented characters). SGML encoding only uses characters from the ISO 646 character set, any other characters are recorded using the entity reference mechanism. It is left up to the user’s browser to display the marks represented by the entity reference. Later in this chapter we discuss how this mechanism can be used to solve a problem with recording end-of-line hyphens, which are an artefact of the original typography of the source document which cannot be completely ignored because of the possibility that they might be real hyphens. In the JITM paradigm the transcription file also contains SGML tagging to conform with the TEI DTD and define the basic logical structure of the transcription. This SGML tagging allows us to identify logical sections of the transcription, while leaving the text of the document clear of tagging. The proposed reference system requires that all SGML tags within the "body" element of the work be uniquely identifiable down to the level of text elements, where a text element is a generic term for a number of existing TEI elements all of which have the property that they only contain text as defined above. The TEI DTD provides for this requirement by specifying an id attribute as one of its global attributes inherited by all elements of the DTD. The global attributes for all TEI elements are as follows;
The values for the id attribute must be legal SGML names, consisting of the letters A to Z, the digits 0 to 9, the full stop, and the hyphen. The name space thus defined is case insensitive. The TEI guidelines recommend a reference system based on a domain style addressing scheme [sect. 6.9.2, Sperberg-McQueen et al., 1994] developed from the hierarchy of element names plus a number when that element type appears more than once at the same level of the document hierarchy. The following example show this id referencing system in use;
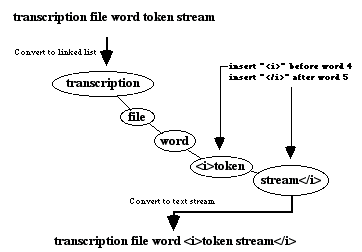
Although this scheme can produce somewhat lengthy identifiers it has the advantage of producing unique identifiers. Its main disadvantage is that any emendment to a document in a normal SGML system may result in the identifiers no longer corresponding to their appropriate position within the document’s hierarchy, unless they are renumbered, which may invalidate any reference links that had been established using the previous identifiers. The proposed scheme makes use of this recommended reference scheme and fortunately does not suffer greatly from its draw backs. Firstly, the authenticated transcription should be static and there should not be any emendments to the file. This presupposes that the creation of the id attributes for the elements used within the text is the last action performed before the transcription becomes fixed. Secondly only the top level of text elements within a transcription file will need to have an identifier, as all other referencing used by the system is implicit, based on the natural granularity of the content of the text elements (i.e. words and characters). The identifier scheme breaks the content of a file up into identifiable text elements containing contiguous strings of word tokens. A word token is defined as all the characters between two word token delimiters, this implies any word that has adjacent punctuation is grouped with the punctuation mark into a single word token. A word token delimiter is any white space (eg. any number of occurrences of spaces, carriage returns, tabs and line feeds). This reference scheme therefore gives us the means for uniquely identifying any text element within a transcription file based on the id of the text element; any word within a text element based on an indexing system using word token number (numbering from the beginning of the text element); and any character within a word based on character position within a word token (numbering from the first character of the word token). The JITM paradigm’s tag insertion process relies on converting appropriate sections of the transcription file into linked lists, the elements of which contain parts of the text of the transcription. If necessary the text of a list element can be further converted into a linked list for insertion of tags at the character level. This may cause the creation of up to three levels of list where a tag is to be inserted into the body of a word. The following diagram demonstrates the procedure graphically at the word token level.
Figure 1. Inserting tags into content. The use of the linked list means that a piece of text being tagged maintains its indexed location relative to the rest of the text, even after markup code is added. This allows multiple tags to be added to the one piece of text. It is a simple process to convert the linked lists back to a contiguous stream of text for output. Since the underlying file format for the transcription file is plain sequential ISO 646, this implies that all markup to be performed on a file must be done in a single pass through the transcription file, as the linked list for a text element of a marked up file may not be the same as for the original transcription file. This requirement is in fact beneficial to the authentication process, as it ensures that a set of commands that would work for a specific transcription file would most likely not make sense when applied to a modified version of the transcription file. Having identified the natural granularity of the transcription file and determined how the markup is to be applied to the transcription so as to not affect the implied reference scheme, a coordinate scheme based on this reference scheme must be defined so it can used in the proposed JITM system. The following expression defines the reference scheme:
This expression allows us to exactly define any single sub-component of a transcription file. For example " <div-1.p-2:5:2>" Specifies the second character of the fifth word in the second paragraph element of the first division element of the body of the document.4.2 Preparation of the Electronic EditionUnlike some SGML applications, the file format for the transcription files of a JITM-based electronic edition is simple so as to maximise the useability of the files. The transcription files are standard ISO 646 characters with minimal SGML encoding, so that if required, the files can be used with other text processing applications. All the complexity of the electronic edition is abstracted away so that it does not interfere with the readability and authenticity of the transcription file, something which should appeal to the scholarly editor, and as discussed in earlier chapters is not found in current SGML systems. The main file for the electronic edition, called the "header file", holds all the header information for the edition so that any changes need only be made once, but will still effect all transcription files. This also means that changes to the header file cannot corrupt the transcription files. 4.2.1 The Structure of an Electronic EditionThe TEI DTD defines a document as consisting of two main elements. As shown in the example document below they are the "teiHeader" and the "text" elements.
While the text element contains the text and associated tagging of the electronic document, the teiHeader element contains information describing the encoded work so that the text itself, its source, its encoding, and its revisions are all thoroughly documented. The information contained in the teiHeader element is analogous to the title page, acknowledgments and other such material found in the beginning of paper-based book and is essential information to literature scholars. A complete teiHeader consists of many subelements and each element can have many attributes. One important aspect of this project is to simplify the files that scholars work with in preparation of an electronic edition, and so to this end we separate the teiHeader from the text of the edition so that it does not complicate the process of preparing the text. This separation is done by using parameter entity references for the elements of the edition that contain the content that is to be processed by the Just In Time Markup system. The following example demonstrates this;
This example, when instantiated by the user’s browser would, only contain the content of the first chapter of the work, the second and third chapters being excluded because of the " IGNORE" value of the parameter entities. Users of the proposed system would be able to modify this file either directly or using some utility without any fear of modifying the authenticated transcriptions as they are stored separately.4.2.2 File Format Specification for Transcription FilesThe user should separate the work up into components of a manageable size based on any obvious structure of the work (eg. chapters for a prose work or individual poems in a poetry anthology). The following is an example of a piece of prose marked up as required for the proposed system:
The text within the elements has to conform to certain restrictions as defined formally below:
These constraints require that the transcription files are thoroughly checked before they can be used in preparing tagRecord sets, but since these files must be rigorously authenticated anyway there is not much extra overhead involved in conforming to these requirements. 4.2.3 Real world considerations for data preparationThe transcription of the original document into the digital medium brings up some considerations which should be discussed. Generally these considerations are concerned with the capturing of the physical layout of the original document (i.e. pagination, lineation and hyphenation), which is useful initially, but becomes inconvenient later on in the development of the edition. The transcription process can be used to capture information about the physical nature of the text being transcribed more efficiently than post processing. Recording this information can be done easily by the typist entering a carriage return at the end of each line in the source and indicating a new page by some inserted code. These two typographical elements of the original document are quite often used in proofreading the electronic edition to help refer back to the original. However this information should not be kept in the file as it is irrelevant to the content of the electronic edition. This implies the necessity of developing utilities for stripping out typographic information entered by the typist, and converting this information to meta-data command sets for application later if required. In practice it has been found that converting lineation and pagination into the TEI milestone tags " <lb>" and "<pb>" respectively is the best solution as they can be easily added into a perspective view at a later date without causing any problems with parsing the document.The following examples show an extract of an original input file and how the milestone tags can be generated and turned into tagRecords; Original Transcription:
After inserting the TEI milestone tags;
After extracting the tags;
The resultant tagRecords;
This example brings up the interesting question of end-of-line hyphenation. Before the introduction of proportional fonts, justification of text in printed matter was often done by breaking words at the end of a line with a hyphen inserted into the text to indicate that the word continued on the next line. In most cases these hyphens are most likely artifacts of the lineation of the text and should be excluded in the electronic edition where the lineation will be dependent on the size of the window in the user’s browser. However if the user wishes to view the document with the original lineation these end-of-line hyphens need to be reapplied in the correct positions. Another aspect of this problem which makes its solution more difficult is that it might be the case that a hyphen appearing at the end of a line is a true hyphen and therefore should appear in all readings of the text. How is this handled? Leaving all hyphens in the text means that when the text is viewed without the original lineation the text will have to be pre-processed to remove all hyphens which are classed as end-of-line and leaving all hyphens which are classed as true hyphens. This means indexing the positions of all hyphens and recording whether or not they are conditional. Conservatively this could mean maintaining a database of hundreds of records and reducing the usefulness of the transcription files for people who do not have access to this database or the means to preprocess the file. Conversely the end-of-line hyphens could be removed from the transcription file and added when appropriate. All real hyphens would remain, and end-of-line hyphens which were deemed to be a true hyphens would therefore stay in the transcription file. The prototype developed for this project uses this method as it requires keeping and maintaining far less information. For a perspective which included the lineation of the original source the end-of-line hyphens would be added along with the lineation tags. The prototype allows for the embedding of text other than SGML tags into the transcription file. As discussed in Section 4.4.1 "Structure of the Command Sets" the content of a tagRecord is embedded into the appropriate location of the transcription file. In the case of a line break tag where the tag breaks a word the embedded string includes a hyphen character. Another possible solution to this problem uses entity references. Since entity references are need in the transcription to represent characters not available in the ISO 646 character, set it is possible to use the same mechanism to represent end-of-line hyphens without adding much more complexity to the JITM paradigm. Entity references are pre-processed by the user’s SGML browser based on specific definitions. Basically the entity reference in the text is replaced with the appropriate character by the browser. A possible solution to the end-of-line hyphen problem is to embed an entity reference for the character into the transcription file. Normally when a perspective is created which does not show the lineation of the original document the entity reference for the end-of-line hyphen would be defined as the null character. However when the lineation was required the entity reference would be defined as the hyphen character. End-of-line hyphens which were true hyphens would need to be recorded as true hyphens in the transcription file. Handling end-of-line hyphens is a basic problem in the creation of the transcriptions of the states in a critical edition whether it is in an electronic or paper-based format. Generally the editor must look at the specific word usage in the entire text and make a decision on this usage. Concordance programs help with this task, but since hyphenation is one of the less well defined and adhered to aspects of grammar this can be a difficult task. The difficult nature of this task proves to be a potential problem for the implementation of the proposed system as the establishment of the authenticated text early on in the development of the edition is essential. This means the editors have to start making decisions about end-of-line hyphens earlier in the process than is their wont. It is hoped that further work with scholarly editors on this issue will bring about an easy solution to this problem. 4.3 Content AuthenticationAs mentioned earlier, the proposed JITM paradigm depends on the transcription files being static so that the character strings held in the tagRecords in the command sets can be inserted into the correct places in the transcription file. To make sure this occurs, a JITM system needs to be able to check that the transcription file to which the tagRecords are going to be applied is the same as the file that was used to generate the tagRecord. If this is not the case the tags may be inserted incorrectly. This means that the authentication of the transcription files is essential to the correct operation of a JITM system. The JITM paradigm’s authentication scheme continues the abstraction theme used in the rest of the paradigm. The transcription files are not altered in anyway to support the authentication scheme. Therefore the files cannot possibly be altered by this scheme. With invasive authentication schemes such as digital signatures new versions of the files would have to be created if there were a change in software, algorithms, or even document ownership thereby creating new states of the transcription files with all the disadvantages that entails for future scholars. The authentication mechanism is very simple compared to the more advanced message authentication schemes in use today. However, since it is only concerned with providing a level of trust that the transcription files that are being used have not been modified, it should be sufficient for the task. The scheme uses a mechanism similar to a Manipulation Detection Code (MDC) as described in section 3.2.2 "Digital Authentication Technology". The reference MDCs would be calculated from the transcription files of the edition using a publicly known hash function. Anyone wishing to authenticate a transcription file would use the same hash function on their copy of the files and if the results matched then they could be reasonably sure that the files had not been modified. Because the JITM paradigm is so dependent on the static nature of the transcription files used, the reference MDCs mentioned earlier are incorporated into the tagRecords used for creating perspectives in a JITM system. It would be an illegal action for a JITM system to embed tags into a transcription file in the circumstance where the MDC recorded in a tagRecord does not match the MDC calculated for the transcription file. Therefore the user is immediately made aware that some element of the document system is not authentic. A disadvantage of this system is that the user confronted with a single invalid tagRecord does not known where the problem might lie. The source of discrepancy might lie in one of three places; the tagRecord, the MDC calculation of the transcription file, or the transcription file. Normally it would be a simple matter to discover which of these factors was not authentic. In the case of a single tagRecord being wrong, a simple comparison with other valid tags would indicate that the MDC recorded in the tagRecord was incorrect. If the utility or algorithm used for calculating the MDC of the transcription file were wrong then all tagRecords for this and any documents used in the JITM system would most likely be deemed invalid. Lastly if the transcription file in question has indeed been modified then the JITM system should work for other documents, but not with the suspect document and therefore it should be replaced. Since the authentication technology is abstracted from the transcription files this also means that the software used for authentication can be changed. This has some advantages but possibly also some disadvantages. These will now be briefly discussed. Being able to change the authentication technology without having to change the transcription files means that the authentication scheme of the JITM paradigm is proof against changes in software as long as the abstracted nature of the authentication scheme is maintained. The main disadvantage being that new algorithms may invalidate the MDC values stored in existing tagRecords. However, it should be a simple task for the tagRecords to be suitably modified so that they contain the new MDC value as calculated from the transcription file. In fact it is possible that different MDC algorithms could be used by different people as long as they did not try to share tagRecords. This leads us to a subtle strength of the JITM paradigm. One of the paradigm’s advantages is that users can develop their own tag sets and swap them to increase the range of perspectives that can be generated for a document. Since the MDC of a tagRecord is that of the transcription file used to create it, imported tag sets can be used as a quality check for other JITM systems. If a tagRecord proves to be invalid when used on another copy of the transcription file with the same MDC algorithm, but is valid on the system that created it, then one of the systems has a corrupted. The users can then discover which document is corrupt and replace it with an archival copy. This process should prevent the proliferation of corrupt states of the transcription files within the community. 4.4 Preparation of Command SetsThis section details how the commands sets used in creating perspective documents for the edition are formally defined. Generally a command set contains the information for one specific feature (eg. lineation for a chapter) so that sets of features can be defined as a list of files, making it easier to access the information. 4.4.1 Structure of the Command SetsIn keeping with the use of SGML for this project, the Command Sets have been defined as a document type and have their own DTD as shown below. A written description follows with examples:
The command set is made up of one or more tagRecord elements. The content of a tagRecord element is the string of characters to be inserted into the transcription file that the tagRecord modifies. The example below shows a typical tagRecord.
The " %tagS;i%tagE;" in between the start-tag and end-tag of the element is the string to be inserted into the transcription file. The string will be processed before insertion to turn the entity references "%tagS;" and "%tagE;" into the system defined stago and tagc delimiter strings and then inserted into the transcription file in the manner and at the position defined by the element’s "action" and "pos" attributes. This step is required so that markup tags can be incorporated into tagRecord elements without destroying the syntax of the element. A more formal definition of the DTD and examples are to be found in Appendix B.The use of entity references in the tagRecords can also be used to help format the perspective. An example of this used in the demonstration prototype provided with this report is that the tagRecords for lineation include an entity reference for a carriage return (i.e. " %return;" ), so that the perspective appears lineated as the user would expect.4.4.2 Abstracting the Typography of the OriginalThe authentication of the transcription from the original source means that lineation and pagination should be maintained in the electronic transcription to aid in referring to the original. Having authenticated the transcription, this typographical information can be abstracted out of the electronic document to become the first set of meta-data associated with the electronic edition. In this case the MDC for the transcription file is unknown. Therefore the file will need to be processed so that the positions of the tags are recorded then the MDC for the transcription calculated so that fileKey can be incorporated into each tagRecord. TagRecords for other features of the edition will not have this problem as the MDC for the transcription file will now be known and fixed. 4.4.3 Recording Meta-dataThe easiest way to record meta-data for the creation of command sets is to allow the creator of the meta-data to modify a copy of the transcription file, and then extract the tags, storing the information as tagRecords. To prevent the corruption of the transcription file in this process (and avoid corrupting the indexing of the tagRecords), special utilities have to be used which allow new material to be added to the file, but prevent any characters which are part of the original content file from being modified or deleted. This also means that no new word tokens can be added to the file and therefore any inserted text must be associated with an existing word token. The utility developed for the prototype achieves this by monitoring the user’s action while working on the file. All material added to the copy of the transcription file is given a special font attribute to indicate that it is not part of the original and any action on the part of the user which would manipulate text that does not have this attribute is vetoed by the utility with an appropriate warning to the user. When the user has finished marking up the document and parsed it successfully against the TEI DTD then the markup can be extracted from the file and separated out into command sets, one for each type of element that was marked up. 4.5 Implementation of the SystemThis section looks at how a JITM system could be implemented so that it would complement existing SGML-based tools for electronic editions. To promote acceptance of the JITM paradigm it should impact the user’s environment as little as possible while still providing a greater versatility and proof of authenticity than existing systems. 4.5.1 Where JITM slots into the processThe most important aspect of the JITM paradigm, is that the perspective documents that the system delivers are virtual documents created on demand. This means that prior to viewing a JITM perspective the user must give the system some parameters that will be used to create the perspective.
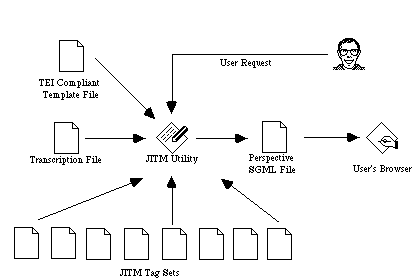
As shown in the diagram above this could be achieved by having the user access a front-end application (the JITM utility). This application would allow them to choose the transcription file and the aspects of the work in which they are interested. The JITM utility would then generate the appropriate SGML file which would be delivered to the user’s SGML-browser. In fact any number of perspective views could be viewed simultaneously on a browser capable of multiple windows allowing the user to compare the different ways of looking at the work under study. This design allows the system to be both stateless and scalable. Once the JITM utility has created the perspective document it does not need to remember anything about the user’s request. The system could therefore be implemented as a stand-alone application on a personal computer or run as a CGI application on a web server. 4.5.2 Data Storage for a JITM Electronic EditionA JITM system has two major types of persistent data, the transcriptions and the sets of tagRecords representing particular types of meta-data. The content of both data types is defined so that they are very portable. This enables the easy repurposing of the files of a JITM system. Transcription files are specifically defined so that they include little extraneous text so that they can be used in other systems. Similarly, sets of tagRecords stored as files can have their own uses. Users of a JITM system can transfer tag sets without having to transfer transcription files because the JITM paradigm ensures that the application of the tag sets authenticates the transcription files. However the highly structured nature of the tag sets makes them eminently suitable for storage in a database. Storing the tag sets in a database would give the user access to the powerful search and retrieval features of the database for searches on the meta-data associated with the transcription. The use of a database would also allow the information contained in the tagRecords to be stored in a more efficient manner. In the JITM system, each tagRecord holds a large amount of redundant information. This is required because a tagRecord may at some point be required to supply all this information to a JITM system that wishes to verify the record and process it. If the parameters of each of the tagRecords are stored in database fields, the redundant information need only be stored once, and inserted into each tagRecord when output from the database. This also reduces the possibility of the incorrect coding of a tagRecord which may go undetected in a tag set created by normal means. Use of a database for the storage of JITM tag set data would also allow global changes to the data to be made efficiently. Depending on the design of the database, it should be possible to reduce the occurrences of duplicated data, thereby reducing the number of places the value would need to be changed if this was required. For example, if an edition were under development, and the fileKey of a transcription file needed to be changed, then with a relational database it would be possible to update all tagRecords for that file by changing one field in the relational database. Another advantage of using a database to store the tag set parameters is to enable cross-chapter selection of tag sets. The current JITM system design keeps a close connection between the tag sets and the transcription file they refer to (normally a chapter of the state). If the parameters for the tag sets of an entire work were stored in a single database then this would facilitate cross-chapter searches. For example, one could do a search for the number of speeches (and their locations) that a particular character does in a state. This facility is certainly available in current systems, but they must search through the entire document to find the result. A database search would be much faster. Despite the advantages of using databases for storing JITM meta-data it is important that any JITM system maintains the capability to output its data types in the simplest of data formats. By using the lowest common denominator approach this will in turn prolong the usefulness of the information for archival purposes. Tying the meta-data to some proprietary data format would possibly limit its long term usefulness. |